
A new era of enterprise search for facilities
(Part II): Data preparation
In Part I of this series, we saw how a knowledge graph, which is a network of concepts connected by their relationships, eclipses traditional databases at the task of traversing relationships and finding information fast. Combine it with AI, and you'll have a very powerful search engine that can understand complex queries and intelligently rank results—just like Google Search, but tailored to your business and data.
Before you migrate over to this system though, you’ll need to do some housekeeping. Hoarding unnecessary data exposes your business to serious risks, so mitigating such tendencies is a critical component of any data governance strategy. In this post, we’ll show you how to deal with some common challenges facility operators face in a data cleanup exercise. Establishing a single version of truth will enhance the ability of your new engineering search platform to deliver the most relevant information. It consists of two parts.
- Removing duplicates
- Finding the latest revisions
Removing duplicates
Even with document control and management systems in place, it’s difficult to maintain strict adherence in a larger team setting, especially if creation and movement of documents are rapid. Consequently, most businesses face high duplication in their data repositories. There are two types of duplication you’ll need to deal with.
Exact duplicates: Documents that are 100% alike. These can be identified fairly easily using hashing algorithms.
Near-duplicates: Documents that are similar, but don’t necessarily have identical content. These could be different versions of a document, or they could be the same version but one is a native copy while the other is scanned, making it appear different to the computer.
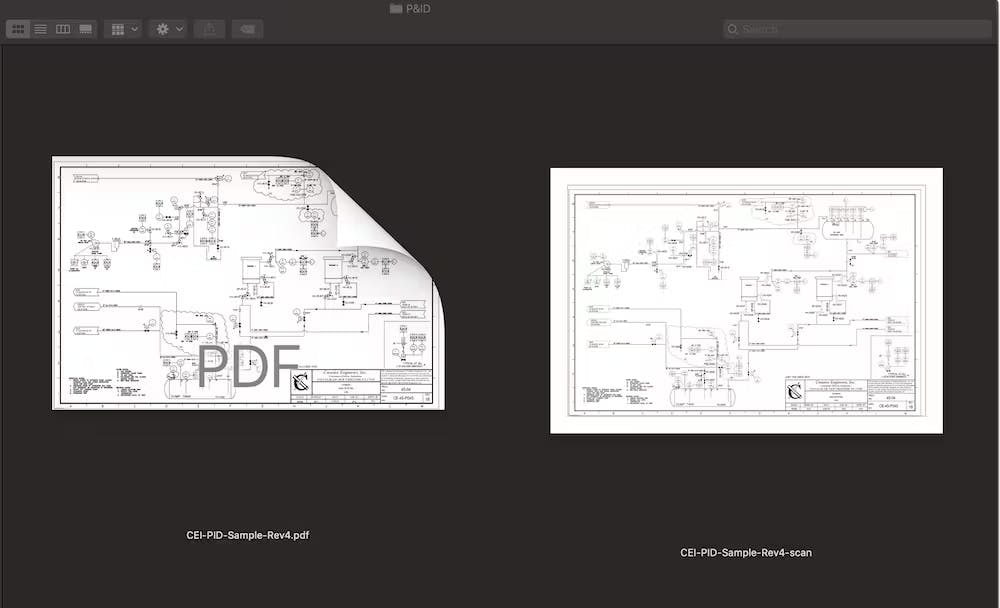
To a computer, this native PDF file and scanned PNG file are different, even though humans can see that the documents are the same.
Finding near-duplicate documents is far more complicated than identifying exact duplicates. It requires a combination of text and image machine learning algorithms to analyze the data. Text is a particularly challenging format to deal with due to the complexity of natural language. It’s fallible to simply compare documents and count the number of matching words because the order in which those words appear also matters.
Computational efficiency is another factor to consider when examining documents for both exact and near-duplicates. If you don’t have good algorithms and infrastructure in place, the comparison can be very slow because you need to compare each document to every other document in the repository.
The best approach is to pass your documents through several filters of similarity, with each step increasing in computational cost for higher accuracy on the narrowed results.
Finding the latest & best versions
Once you’ve removed all of your duplicates and near-duplicates, you can move on to identifying the latest and best quality version of each document. In general, you can look for revision codes and dates within the extracted document text. Looking at file metadata (like “creation date”) alone could lead to false conclusions as someone could have made a recent copy of an early version of the document, giving it a later creation date compared to the actual latest version of the document.
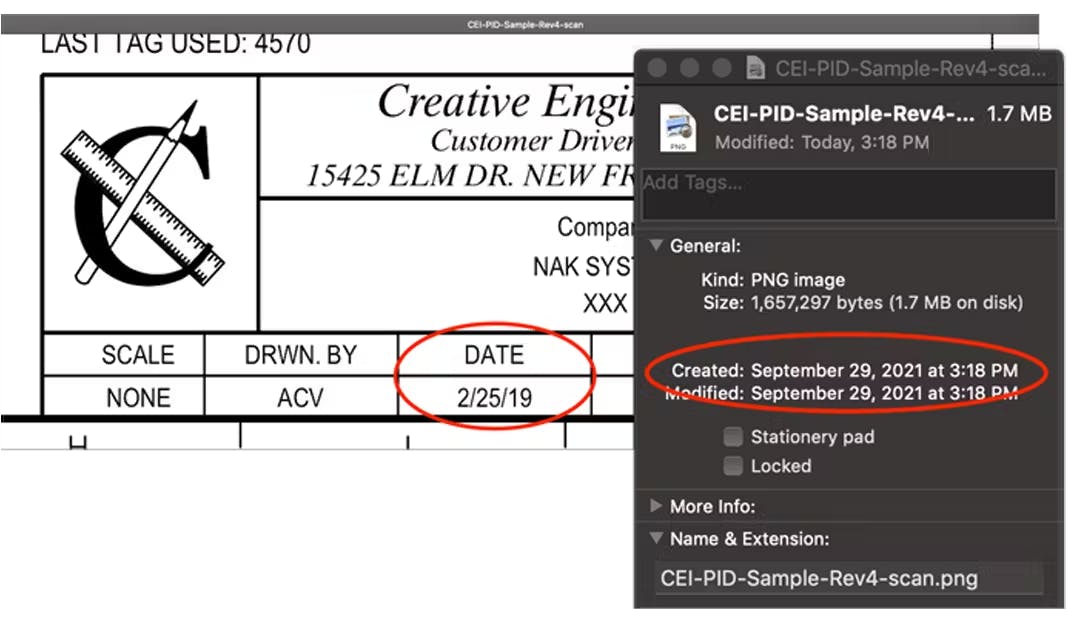
File creation dates don’t always reflect the true version date.
However, there are also challenges when examining the information within the document, especially if the document required Optical Character Recognition (OCR) to make it readable. State-of-the-art OCR software will have inbuilt spellcheckers to minimize errors, but spellcheck rules are difficult to apply to dates and codes. You will also need a separate algorithm to associate the revision code with the correct date if it’s stored in a tabular format. AI will be very useful to help filter through large numbers of documents, but it’s still necessary to bring a human in at the final stages to verify the results—especially if precision is critical, as is often the case with engineering data.
Besides determining the latest version of each document, you’ll also want to make sure you have the best version. Generally, you should choose documents that are machine readable over scanned ones. If all copies of a document are scanned, you can run image quality algorithms to assess the best one.
Clean data mitigates risk
Data cleanup is a tedious and challenging, but essential task. Failing to establish a single version of truth for your data could cause employees to make decisions based on outdated or incorrect information, leading to serious implications down the line. Fortunately, AI combined with quality control through human verification can help you overcome many difficulties efficiently. If you have an inhouse data science and computer engineering team, you’re all set to forge ahead on your own. For those without (or if your data science team is overloaded with other projects), the Cenozai team is well versed in helping facility operators prepare and migrate critical engineering documents for Industry 4.0 standards—feel free to reach out to us. In the meantime, stay tuned for the third and final article in this series, exploring various use cases for a search engine powered by knowledge graphs.
Recommended Posts

8/1/2024
A new era of enterprise search for facilities
Enterprise search is changing for facility operators—out with the file hierarchies and in with the information networks.

12/16/2022
Industry 4.0: The Unstructured Data Perspective
How to build a contextual platform that will be the launching pad for every one of your Industry 4.0 initiatives.

8/9/2022
Data hoarding is a major risk for
facility operators
Data hoarding is widespread, and has a major impact on business performance. What’s the problem, why does it happen, and how can you fix it?